それでは引き続きアミノ酸ネタから、個人的にちょっと気になっていた、「アミノ酸は20種類あるけど、それぞれどんな割合で使われているんだろう?」というポイントに入っていくといたしましょう。
そもそもその話は、消化酵素ペプシンの認識配列が、[DE]-[FWHY](ついに一文字表記を当たり前のように使い始めましたが(笑)、思い出していただけると幸いです)という2連続のアミノ酸だったわけですけど、これを、
「それぞれ2/20と4/20なので、1/50の確率でペプシンが切断する配列が登場することになるわけですね」
…などと書いていた点に関して、
「正確には、各アミノ酸の出現頻度は同じではないので、そう単純にはならないんすけど」
…と補足を入れていたのが発端で、じゃあ正確な頻度はどのぐらいなんだよ、って話を見てみようというネタですね。
僕自身、「メジャーなアミノ酸・レアめなアミノ酸」という違いの大まかな印象はあるわけですけど、正確な数値を見たことはなかった気がするので、今回調べてみよう、という話になります。
早速「amino acid frequency」(アミノ酸頻度)で検索してみたところ、そのものズバリなページがヒットしてきました!
後半に、20種類のアミノ酸が登場する「出現頻度グラフ」が紹介されていますね。
しかし、詳しい説明がなかったので、「どんなグループのアミノ酸なのか」が不明だったため、参考文献として挙げられていた論文を見てみたところ、ズバリ元ネタが見つかりました…
こちら、進化に関する話をアミノ酸と絡めて見た「Non-Darwinian evolution(非ダーウィン進化)」というタイトルの、まさかの1969年の論文(↓)が元ネタ…!
古い論文で、当時の雑誌をスキャンしたPDFファイルしか存在しませんでしたが、説明文込みの方がいいかなと思ったので、元論文の図をサイエンス誌のPDFから引用紹介させていただきましょう。
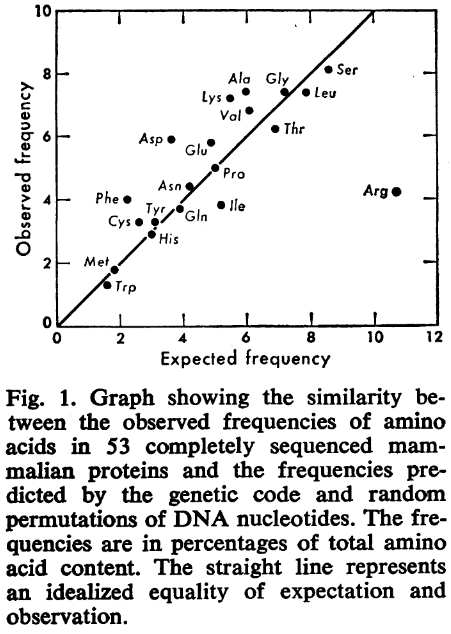
…そう、なぜか二次元のグラフで、横軸縦軸は何を意味しているのかといいますと、まず分かりやすい縦軸が、実際のアミノ酸の出現頻度になります。
つまり、横の広がりはいったん無視して、上から下まで見ていった際、一番上のやつが一番出現頻度が高いアミノ酸ということで、これはズバリ、セリン(Ser)になるわけですね。
(その次が…微妙ですが、アラニンでしょうか……順に減っていって、一番下にいるのはトリプトファン、これは個人的にも予想通りといえます。)
では横軸は何かと言いますと、これは「理論上の想定出現頻度」ということで、これは一体どういうことなのでしょうか…?
これを考えるには、コドン表を知っておく必要がある感じになっています。
コドン表というのは、「DNAの3文字がどのアミノ酸に対応するか?」ということをまとめてくれた表なわけですけど、これは何気に、ずーっと前の分子生物学入門シリーズの記事で紹介したことがありました。
ちょっとボヤけていてあんまりいい画像じゃないですけど(借りておいて酷い言い草ですが(笑))、まぁシンプルにまとまっているので、せっかくなので大手試薬会社のナカライからお借りしたこの画像をそのまま再掲させていただきましょう。
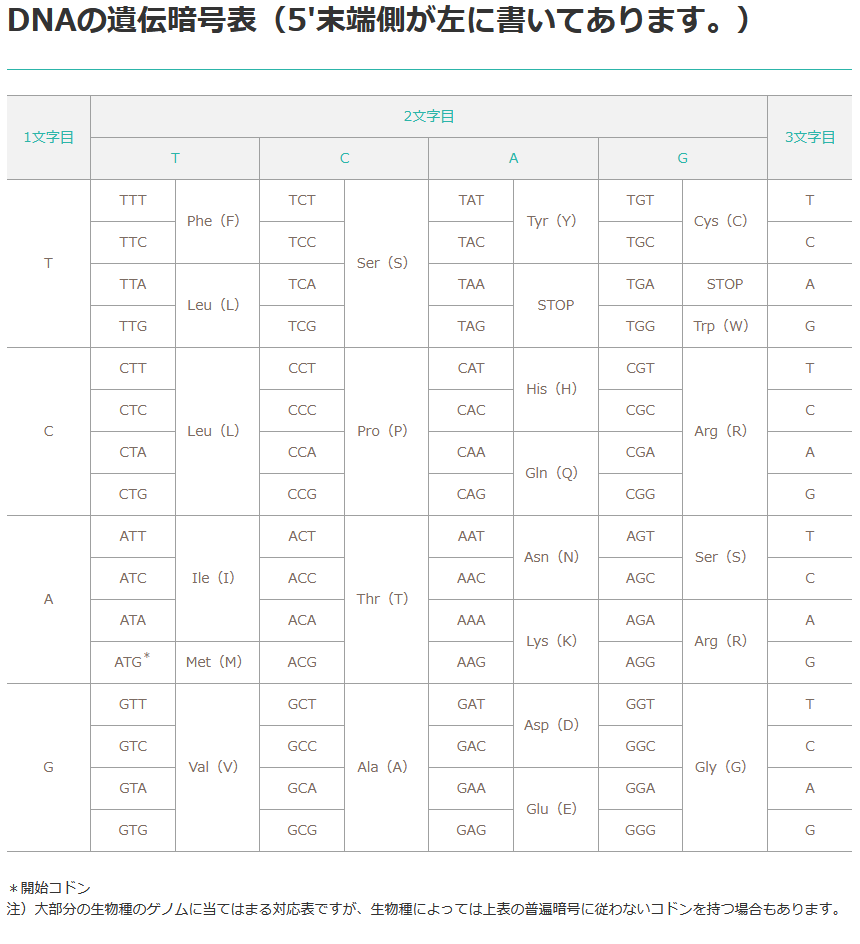
…直感的に分かるようなデザインになっているので再度の説明も不要に思いますが、1文字目が左側で大きく4分割、2文字目が上部で、表を垂直に4分割、そして最後3文字目が右側で各1文字目のフィールドを小さく4分割している形で、4×4×4の合計64分割されたテーブルになってるわけですけど、例えばTTTというDNA3文字は、一番左上、フェニルアラニン(Phe)を指定するコドンだ、CATなら…順番に左から見ていって、ヒスチジン(His)だね……という具合にまとめられている感じですね。
このコドン表は、絶対的なルールはないものの、基本的に世界中どこで作られたものでも、この並びになっていることがほぼ100%に思います。
つまり、T→C→A→Gの順に並んでいるので、どんなコドン表でも必ず左上がフェニルアラニン、右下がグリシンで、ストップコドンは右上の方にあるように配置されている…という感じで、何度も飽きるほど見てコドン表に慣れた学生は、大体の位置でももうコドンとアミノ酸の関係を思い出せるぐらいになっている感じだといえましょう。
まぁこのフォーマットになる理由は、もちろんこの形式だとちょうど上手いこと同じアミノ酸がまとまっていることが多いから、ってのが一番かと思うんですけど、何気に実は、歴史的に一番最初に判明したコドンが(こないだも一言だけチラッと書いていましたが)TTTのフェニルアラニンであり、その次がCCCのプロリンで、次に確か「CACACACA…」というCとAの連続DNAを使ったら、ヒスチジンとスレオニンが大量に作られてきた……という流れで、ひとつずつコドン表を解明していったという流れだったように記憶しているんですけど、ちょうどその「判明した順番」、つまり人類がコドン=アミノ酸のレシピを知った順番に並んでいるとも言えるんですよねぇ~。
唯一、セリン(Ser)とアルギニン(Arg)だけがちょっと飛び石状態になってるんですけど(あと停止コドンも)、この並びだと上手いことほとんどの同じアミノ酸が連続で並ぶようになっていて、発見の歴史と表のキレイさとが奇妙な一致を見せている、科学の奇跡の一種にも思えます。
(例えば、アルファベット順の通りA>C>G>Tという並びで描くと、最初の左上4つのPheとLeuは、上から順にLeu>Phe>Leu>Pheと飛び飛びで配置される形になってしまうわけですが、いつもの並びだとキレイにそれぞれ横並びでまとまるわけです。よく考えたら、結構奇跡に思える感じですね…!)
と、コドン表についてももうちょうい触れたかったのですが、またしてもあまりに時間が押しているのでせめて横軸の話にまで戻っておくと、こんな感じでパッと見でも分かる通り、各アミノ酸は対応コドンの数に差があるわけですね。
具体的には、メチオニンMetはたった1つ、ATGしかコドンがないのですが、ロイシンLeuなんかは、なんと6つも対応コドン持ちという、随分と欲張りなやつになっているわけです。
で、例のグラフの横軸ですけど、これは、「理論上、対応コドンの数から言って、もしもDNAがランダムに並んでいるものなら、この確率でそのコドンが出てくるはず」というものをプロットしたものになっているわけですね。
つまり、MetとTrpはコドンが1つしかないですから、理論上、DNAが並んでいる遺伝子上でも出てくる確率がかなり小さい=横軸はかなり小さい場所に位置しているわけですけど、ArgなんかはこちらもLeu同様対応コドン6つ持ちなので、理論上いっぱい登場してきて当たり前なアミノ酸になっているわけです。
ちなみに、同じ「6つ持ち」なのに、LeuとArgと、あともう1つの6種持ちであるSerの横軸の位置が違うのはなぜ?と思われるかもしれませんが、実はDNAの各4塩基の存在比自体にも差があるというのがその理由で、記事によると、
22.0% uracil, 30.3% adenine, 21.7% cytosine, and 26.1% guanine
という比だそうですから…
(ちなみにウラシルはDNAでいうとチミン=Tです)
アデニンAとグアニンGの存在比は、チミンT(ウラシルU)とシトシンCよりも結構、最大で1.5倍ぐらい大きくなっているため、AとGをふんだんに使っているArgが、理論上一番登場してくることになりますね、という形であの位置関係になっているということでした。
で、見て明らかな通り、そんな「圧倒的、一番登場して然るべき」なArgが、実際の出現頻度は地味にかなり低い(縦軸が低い)のが見てとれるわけですけど、これが一体何を意味するのか…??
…と、そんな中途半端なところで、完全に時間切れとなってしまいました(笑)。
本題に入れなかったにも程がありますが、今回は「久々にコドン表を見て、ちょっとコドン表について語った回であった」という感じで、続きは次回にまわさせていただこうと思います。