こないだの付録記事・キャラの関係性分析ネタで、「Frankさんの公開資料にもう少し詳しい話があるので、またおまけのおまけで見させてもらおうかと思う」と書いていましたが、今回はそちらに触れてみようかと思います。
前半の、Pythonプログラミング・コードの話とかは不要かなと思いましたが、まぁせっかくなので(ただ説明文を日本語にして、コードはコピペしただけですが)こちらもそのまま掲載しておきました。
途中、こないだの記事と同じ内容があるけどまぁそれもそのまま貼るとして、数字込みのグラフがやはり面白いネタといえそうですね。
意外とかなりボリュームがあったので(コードを無視しても、結構な量)、早速参りましょう。
----------
志村貴子『青い花』における登場人物およびその関係性の相対優勢度
フランク・ヘッカー
2022年3月7日
導入
『そっち系のひと:志村貴子『青い花』に関する考察』を執筆する過程で、この作品に登場する全ての登場人物と、その登場ページの完全な索引を作成した。本ドキュメントでは、この登場人物索引を使って、作中に登場するキャラクターとその関係の相対的な優勢度を示すソーシャルグラフを作成する。
統計ソフト『R』や、データ操作やプロットに用いるTidyverseやtidygraphといった追加ソフトに馴染みのない読者のために、様々なステップについての補足説明を加えた。より詳しい情報は、Tidyverseについて学べる様々な情報を確認されたい。
設定方法
登場人物索引の解析にはPythonのプログラムを用いるので、まずターミナルウィンドウでPythonの仮想環境を構築する:
virtualenv .env
source .venv/bin/activateまた、仮想環境に設定したPythonのバージョンを強制的に使用するために、以下の行を含むファイル【.Rprofile】を作成する:
Sys.setenv("RETICULATE_PYTHON" = ".venv/bin/python")(ここで、Rセッションを再起動する必要がある。)
次に、以下のRライブラリをロードする。それぞれの目的は以下の通り:
- tidyverse:一般的なデータ操作とプロットを行う。
- reticulate:Pythonのコードを実行する。
- tidygraph:ネットワークデータオブジェクトを作成し操作する。
- ggraph:tidygraphによって作成されたネットワークデータオブジェクトをプロットする。
- flextable:表形式データを表示する。
- gtools:quantcut()関数を用いる。
- tools:MD5チェックサムを計算する。
library("tidyverse")
library("reticulate")
library("tidygraph")
library("ggraph")
library("flextable")
library("gtools")
library("tools")
データの準備
登場人物索引ファイルの入手
ここでは、省略なしの登場人物索引(Markdown形式で書かれている)のローカルコピーを使用する。(オリジナルファイルは、『That Type of Girl』の公開ソースリポジトリにあるはずである。本ドキュメントの作成時点では、そのリポジトリはまだ存在しなかったが。)
ファイルのMD5ハッシュ値をチェックし、内容が正しいものと一致しない場合は、処理を停止する。
stopifnot(md5sum("char-index.md") == "7d00bec7a2e00c4496b915e84f935391")このファイルは、各登場人物それぞれに1行、名前(または役割)と、括弧付きのコメントがあるかもしれないという形式になっている。その行の後には、そのキャラクターが登場する各ページまたは連続したページ範囲に対して1行ずつ、複数の行が記されている。
登場人物索引からキャラを抽出する
Pythonのコードを使って、このMarkdown形式登場人物索引ファイルを、キャラクターが登場するページ(またはページの範囲)までマッチする行を含むCSVファイルに変換していく。
まず、必要なPythonモジュールをインポートすることから始めよう。
import re
import math
import csv次に、キャラクター名を参照している索引から必要な行を取得し、実際の名前そのものを抽出するPython関数を定義する。
注:解析のデバッグの際に、このファイルを一度に一チャンク(データの塊)として処理できるように、関数定義には空行を含めていない。空行を省くことで、Pythonコンソールでチャンク全体がPython関数定義として適切に扱われるようになる。
def get_character_name(index_entry):
"""Extract character name from index entry."""
#
# We have three possible cases, with a regular expression for each.
# 1. The character has a full name in the format family, given.
full_re = r'^- +\**([A-Za-z]+), +([A-Za-z]+).*$'
#
# 2. The character has a single name (which may be either their
# given name or family name) followed by a comment in parentheses.
single_re = r'^- +([A-Za-z]+) *\(([^)]+)\).*$'
#
# 3. The character is identified in some other way.
other_re = r'^- +(.+)[,:].*$'
#
# We attempt to match the line against all three possibilities.
full_m = re.match(full_re, index_entry)
single_m = re.match(single_re, index_entry)
other_m = re.match(other_re, index_entry)
#
# Check for each case and set the character name accordingly.
if full_m is not None: # Family name, given name
if full_m.group(2) is None: # Shouldn't happen, but..
character = full_m.group(1)
else:
character = f"{full_m.group(2)} {full_m.group(1)}"
elif single_m is not None: # Single name with comment
if single_m.group(2) is None: # Shouldn't happen, but...
character = single_m.group(1)
else:
character = f"{single_m.group(1)} ({single_m.group(2)})"
elif other_m is not None: # Some other format
character = other_m.group(1)
else: # Unknown format
character = ''
#
# Return the name to be used for this character.
return get_display_name(character)中には、特定の表示をさせたい場合(例:「奥平あきら」ではなく「あきら」と表示させたいなど)もあるので、名前を自由に変更できる関数も定義しておく。
def get_display_name(name):
"""Return given names, nicknames, or other special designators."""
#
display_names = {
'Akira Okudaira': 'Akira',
'Chizu Hanashiro': 'Chizu',
'Fumi Manjome': 'Fumi',
'Miwa Motegi': 'Mogi',
'Shinobu Okudaira': 'Shinobu',
'Haruka Ono': 'Haruka',
'Hinako Yamashina': 'Hinako',
'Kagami (husband of Kazusa)': 'Mr. Kagami',
'Kayoko Ikumi': 'Kyoko’s mother',
'Kazusa Sugimoto': 'Kazusa',
'Ko Sawanoi': 'Ko',
'Kuri Sugimoto': 'Kuri',
'Kyoko Ikumi': 'Kyoko',
'Manjome (mother of Fumi)': 'Fumi’s mother',
'Misako Yasuda': 'Yassan',
'Orie Ono': 'Orie',
'Ryoko Ueda': 'Ueda',
'Sakiko Okudaira': 'Akira’s mother',
'Shinako Sugimoto': 'Shinako',
'Yasuko Sugimoto': 'Yasuko',
'Yoko Honatsugi': 'Pon',
}
return display_names.get(name, name)各キャラクターは1つ以上の参照ページを持つことになる。そこで、索引から参照ページを取り出し(巻数を含む)、巻数、最初のページ番号、最後のページ番号(シカゴ・マニュアル・オブ・スタイルのガイドでは、必ずしもページ番号を完全表記する必要はない)の三つ組を抽出する関数が必要である。
def get_volume_pages(ref):
"""Given a page reference, return volume plus page range."""
#
# Page references are of the form x:yyy or x:yyy--zzz where x is
# the volume number, yyy is the first page number in the reference,
# and zzz is the end of the page number range (in CMOS format).
# References may also have a preceding or succeeding underscore,
# and may be followed by additional punctuation or other material
# we can ignore.
ref_re = '^ *_?([1-9][0-9]*):([1-9][0-9]*)(--*)?([0-9]+)?_?[,; ]?.*$'
#
# Look for a page reference.
ref_m = re.match(ref_re, ref)
if ref_m is None:
return (0, 0, 0)
#
# Pull out the volume, starting page, and ending page (CMOS format).
volume = int(ref_m.group(1))
if ref_m.group(2) is None: # Shouldn't happen, but...
return (0, 0, 0)
if ref_m.group(4) is None: # Single page
first = int(ref_m.group(2))
lst = first
else: # Range of pages
first = int(ref_m.group(2))
lst = int(ref_m.group(4))
return (volume, first, lst)最後に、シカゴ・マニュアル・オブ・スタイル (CMOS 9.61)が推奨する表記法に従って記述されたページ範囲を取り出し、それを完全な最初と最後のページ番号に変換する関数を定義する。
def get_first_last_pages(first, lst):
"""Convert CMOS-style page range to first and last page numbers."""
#
assert isinstance(first, int) and first > 0
assert isinstance(lst, int) and lst > 0
if lst >= first: # Second part is the actual page number
last = lst
else: # Second part contains only changed digits from first part
# Compute the number of digits in the second part.
n_digits = math.ceil(math.log10(lst))
#
# Compute base digits of first part, ignoring last n digits.
first_base = math.floor(first / 10**n_digits)
#
# The last page number is that value plus the changed digits.
last = first_base * 10**n_digits + lst
return (first, last)
次に、Pythonのコードを実行して索引ファイルを開き、キャラクターとその登場に関する情報を抽出し、それぞれのキャラが登場する各ページまたはページ範囲が並んだCSVファイル【char-appear.csv】を作成する。
index_path = 'char-index.md'
with open(index_path, 'r', encoding='UTF-8') as index_f:
lines = index_f.readlines()
# Initialize appearances dict. Each entry is a list of ranges.
appearances = {}
character = ''
# Look for characters and record their appearances.
for line in lines:
# Look for character entries.
if line.startswith('- '):
if line.startswith('- ') or '*See*' in line:
continue
character = get_character_name(line)
elif character == '': # Haven't see a character entry yet
continue
else:
volume, first, lst = get_volume_pages(line)
if volume <= 0:
continue
if character not in appearances:
appearances[character] = []
first, last = get_first_last_pages(first, lst)
appearances[character].append((volume, first, last))
with open('char-appear.csv', 'w', encoding='UTF-8') as appearances_f:
appearances_csv = csv.writer(
appearances_f,
delimiter=',',
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
)
for appearance in appearances.items():
for page_range in appearance[1]:
appearances_csv.writerow(
(
appearance[0],
page_range[0],
page_range[1],
page_range[2],
),
)しかし、このCSVファイルは他の目的には有用だが、各行がページ番号またはページ範囲のどちらの場合もあるため、分析には不向きである。
そこで、さらにPythonのコードを使って、各行が、あるページにおけるあるキャラの登場を表すCSVファイル【char-page.csv】を作成することにした。
with open('char-appear.csv', 'r', encoding='UTF-8') as appearance_f:
appearance_csv = csv.reader(
appearance_f,
delimiter=',',
quotechar='"',
)
with open('char-page.csv', 'w', encoding='UTF-8') as page_f:
page_csv = csv.writer(
page_f,
delimiter=',',
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
)
for row in appearance_csv:
for page in range(int(row[2]), int(row[3]) + 1):
page_csv.writerow((row[0], f"{row[1]}:{page}"))そして、【char-page.csv】ファイルを読み込み、【char_page_tb】というデータテーブルに落とし込んだ。
分析
ここまでで、漫画で描かれた全登場人物に対して、あるキャラクターが登場する各ページを示す表が得られたことになる。この表は、今後のすべての分析の基礎となる。
登場人物の優勢度
まず最初に思い浮かぶ質問はこんなものであろう:『青い花』では、各登場人物がどの程度他より目立って描かれているのか?例えば、あきらよりふみの方が登場回数が多いのか、あるいはその逆なのか?また、京子についてはどうだろう?ふみとあきらに比べて、どれくらいの頻度で登場するのだろうか?
これに答えるために、『青い花』の全ページ中、各キャラクターが登場する割合が記録された、char_pct_tbという表を作ったわけである。この表をパーセンテージの降順で並べ替えると、最も優勢度の高いキャラクターが一番上に来ることになる。
N_Appearances <- length(char_page_tb$Page)
N_Pages <- char_page_tb %>%
select(Page) %>%
unique() %>%
summarize(count = n()) %>%
as.integer()
char_pct_tb <- char_page_tb %>%
group_by(Character) %>%
summarize(Page_Count = n()) %>%
mutate(Page_Pct = round((100.0 * Page_Count) / N_Pages, 1)) %>%
arrange(desc(Page_Pct))
N_Chars <- length(char_pct_tb$Page_Count)登場人物索引に掲載されているキャラクターは全部で82名で、漫画全体・1319ページ分の情報が含まれている。キャラクターの総出演回数は3399回なので、1ページあたりの平均描写数は2.6人となる。一人のキャラクターの登場回数の中央値は7ページである。
上位20名のキャラクターが登場するページの割合をグラフにしてみた:
char_pct_tb %>%
head(20) %>%
mutate(Character = fct_reorder(Character, -Page_Pct)) %>%
ggplot() +
geom_col(aes(x = Character, y = Page_Pct)) +
scale_y_continuous(breaks = seq(0, 100, 10)) +
ylab("Percentage of Pages") +
labs(
title = "Prominence of Characters in Sweet Blue Flowers",
subtitle = "Based on the Percentage of Pages in which the Character Appears",
caption = "Data source: \n That Type of Girl, unabridged character index"
) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 60, hjust = 1)) +
theme(axis.title.x = element_text(margin = margin(t = 5))) +
theme(axis.title.y = element_text(margin = margin(r = 10))) +
theme(plot.caption = element_text(margin = margin(t = 15), hjust = 0))
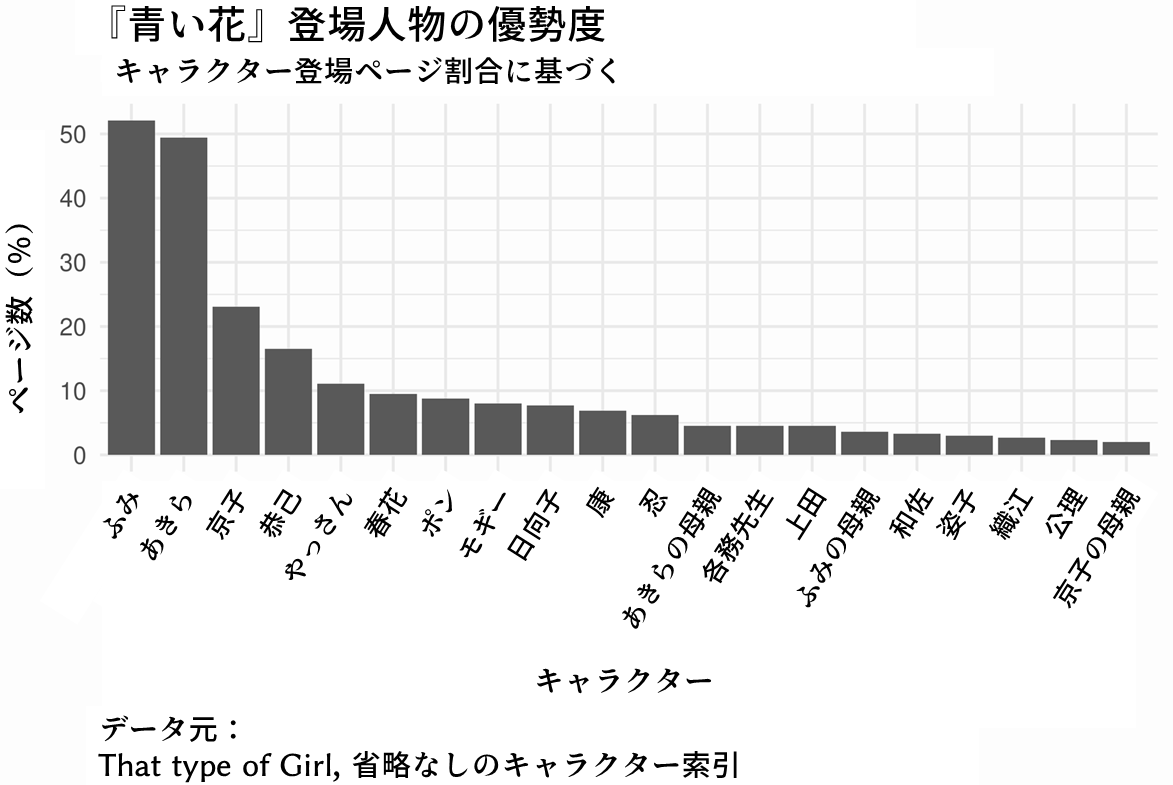
同じデータを表形式で、やはり上位20名のキャラクターのみについて示してみる:
char_pct_tb %>%
head(20) %>%
select(Character, Page_Pct) %>%
flextable(col_keys = c("Character", "Page_Pct")) %>%
set_header_labels(Page_Pct = "% of Pages") %>%
set_caption("Prominence of Sweet Blue Flowers Characters") %>%
autofit()|
登場人物 |
登場ページ(%) |
|
ふみ |
52.1 |
|
あきら |
49.4 |
|
京子 |
23.1 |
|
恭己 |
16.5 |
|
やっさん |
11.1 |
|
春花 |
9.5 |
|
ポン |
8.8 |
|
モギー |
8.0 |
|
日向子 |
7.7 |
|
康 |
6.9 |
|
忍 |
6.2 |
|
あきらの母親 |
4.5 |
|
各務先生 |
4.5 |
|
上田 |
4.5 |
|
ふみの母親 |
3.6 |
|
和佐 |
3.3 |
|
姿子 |
3.0 |
| 織江 |
2.7 |
|
公理 |
2.3 |
|
京子の母親 |
2.0 |
このグラフと表から、先ほどの質問の両方に答えることが可能である。
ふみとあきらはほぼ同じ頻度で作中に登場し、ふみの方がやや優勢であることが分かった。この二名は、全体の約半分に登場している。
次に目立つのは京子で、全体の約四分の一、つまりふみやあきらの半分程度登場する。恭己は全体のおよそ六分の一ほどのページで登場する。
キャラ関係性の優勢度
次に、登場人物同士の関係性について見てみよう。ここでは特に、二人の人物が同じページに登場する場合、その二人を互いに関係があるとみなすことにした。
この基準は誰が見ても同じになるような、完全なものではない―例えば、あるページには、ある登場人物の集団が登場するコマが一つか二つあり、その後、別のキャラクターが登場するコマに移行することがある。しかし、そのような例が比較的少ないのであれば(私はそう思う)、この方法によって見出された「関係」は、マンガの中の実際の関係に比較的近く対応することになるであろう。
また、どの登場人物が他のキャラと関係を持っているかということに加えて、その関係がマンガの中でどの程度重きを置いて描かれているかということも知りたいと思う。この、二人の関係の重要性を示す代用指標として、二人のキャラが一緒に登場するページの数を用いることとする。
ここでは以下のように、キャラの同時登場回数参照表【joint_pct_tb】を構築する:
- 【Page】列を共通項目フィールドとして、【char_page_tb】表を自分自身で結合させる。これで、あるキャラクターAが別のキャラクターBと一緒に登場する(またはその逆)各ページの行を持つ大きな表が作成される。
- 表が結合されるやり方により、結果として得られる表は関係を二重にカウントすることになる。例えば、あきらとふみが第四巻12ページに一緒に登場する場合、結果として二つの行が作成されることになる。一つは、あきらが【Character.x】列、ふみが【Character.y】列に登場する行で、もう一つの行ではそれらの位置が逆になる形である。また、一人のキャラクターが二度登場する行もある。このような二重カウントや自己カウントを排除するために、アルファベット順で最初のキャラクター名が二番目のキャラクター名よりも厳密に前にある行だけを保持する。
- 【Page】列は最早不要なので、削除する。
- 特定のキャラクターペアを持つ行を全てまとめて、そのペアに対応するページの数をカウントし、その数を【Page_Count】列に格納する。
- 作中の全ページ数に対する登場ページ数の割合を表す、二つ目の新規列【Page_Pct】を作成する。
- 更に新しい列【Pair】を作成し、二人の登場人物の名前を一つの項目にまとめる。
- 出来上がった表を【Page_Count】の値で降順にソートする。
joint_pct_tb <- full_join(char_page_tb, char_page_tb, by = 'Page') %>%
filter(Character.x < Character.y) %>%
select(!Page) %>%
group_by(Character.x, Character.y) %>%
summarize(Page_Count = n()) %>%
ungroup() %>%
mutate(Page_Pct = round(100.0 * Page_Count / N_Pages, 1)) %>%
mutate(Pair = paste(Character.x, Character.y, sep=' / ')) %>%
arrange(desc(Page_Count))
N_Jt_Appear <- length(joint_pct_tb$Pair)
N_Max_Jt_Appear <- (N_Chars * (N_Chars - 1)) / 2登場人物の内、共同出演が見られたのは350組である。これを、全てのキャラが他の全てのキャラと少なくとも一度は一緒にページに登場した場合の、理論上の最大組合せ数である3321組と比較してみる。つまり、作中で実際に実現されているのは、理論上可能関係なペアの内、わずか11%に過ぎない。
一組のキャラクターが共同で登場する回数の中央値は、3ページである。
そして、『青い花』全ページの中で、特定の二名が一緒に登場する割合の内、上位20位までのペアをグラフにしてみた。
joint_pct_tb %>%
head(20) %>%
mutate(Pair = fct_reorder(Pair, -Page_Count)) %>%
ggplot() +
geom_col(aes(x = Pair, y = Page_Pct)) +
scale_y_continuous(breaks = seq(0, 100, 10)) +
xlab("Character Pair") +
ylab("Percentage of Pages") +
labs(
title = "Most Prominent Relationships in Sweet Blue Flowers",
subtitle = "Based on Percentage of Pages in which Characters Appear Together",
caption = "Data source: \n That Type of Girl, unabridged character index"
) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 60, hjust = 1)) +
theme(axis.title.x = element_text(margin = margin(t = 5))) +
theme(axis.title.y = element_text(margin = margin(r = 10))) +
theme(plot.caption = element_text(margin = margin(t = 15), hjust = 0))
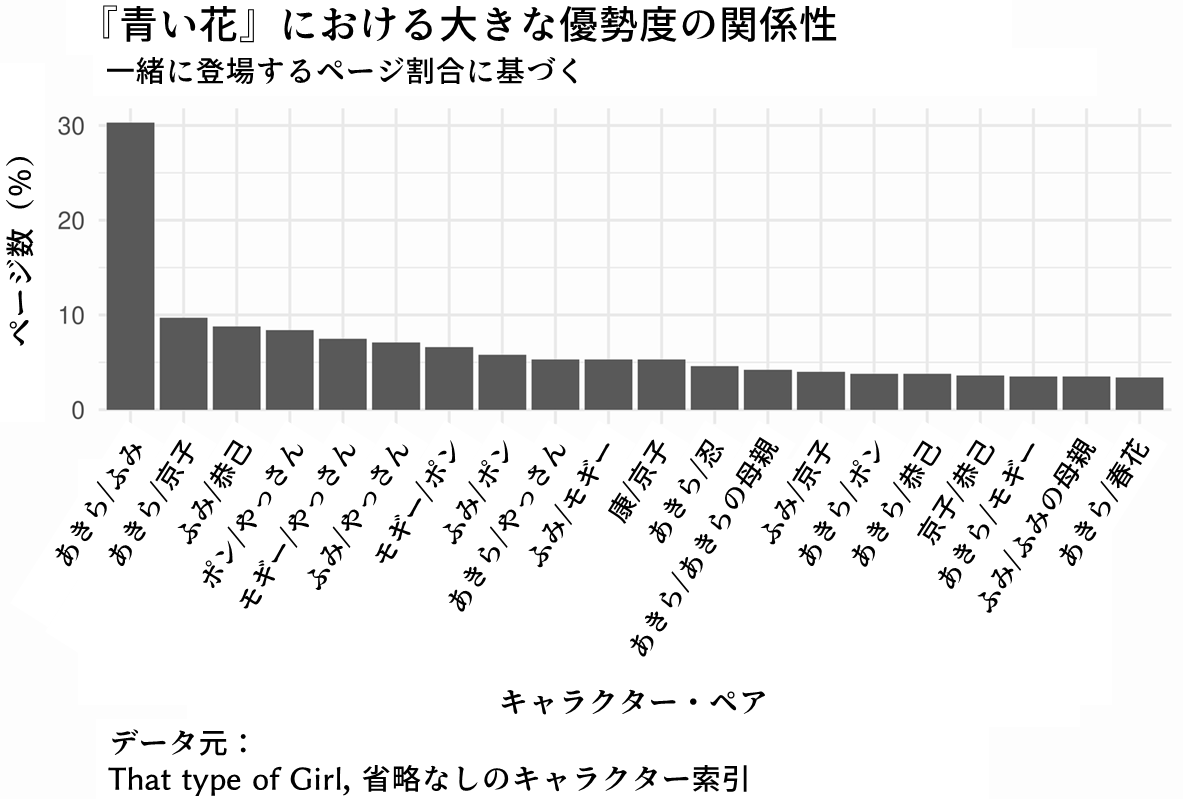
同じデータを表形式で、やはり上位20組のペアのみについて示してみる:
joint_pct_tb %>%
head(20) %>%
select(Pair, Page_Pct) %>%
flextable() %>%
set_header_labels(Page_Pct = "% of Pages") %>%
set_caption("Prominence of Sweet Blue Flowers Relationships") %>%
autofit()『青い花』関係性の優勢度
|
ペア |
登場ページ(%) |
|
あきら/ふみ |
30.3 |
|
あきら/京子 |
9.7 |
|
ふみ/恭己 |
8.8 |
|
ポン/やっさん |
8.4 |
|
モギー/やっさん |
7.5 |
|
ふみ/やっさん |
7.1 |
|
モギー/ポン |
6.6 |
|
ふみ/ポン |
5.8 |
|
あきら/やっさん |
5.3 |
|
ふみ/モギー |
5.3 |
|
康/京子 |
5.3 |
|
あきら/忍 |
4.6 |
|
あきら/あきらの母親 |
4.2 |
|
ふみ/京子 |
4.0 |
|
あきら/ポン |
3.8 |
|
あきら/恭己 |
3.8 |
|
京子/恭己 |
3.6 |
|
あきら/モギー |
3.5 |
|
ふみ/ふみの母親 |
3.5 |
|
あきら/春花 |
3.4 |
ご想像通り、ふみとあきらの関係が、最も優勢で重きを置かれたものであることが分かった。この二人は、作中のほぼ三分の一のページで一緒に登場している。また、あきらと京子並びにふみと恭己の関係がそれに続く優勢度を占めているものの、作品全体の内、十分の一以上を占める関係性は他に存在しなかった。
関係性の優勢度と強さ
ちょっとした余談:上述の通り、この関係性の分析では、その優勢度(顕著さ)、すなわち、そのペアが漫画作中でどれだけ頻繁に描かれているかを測定している。これ以外に、二人のキャラクターが同じページに描かれる頻度と、どちらか一方が他方の描かれていないページに描かれる頻度とを比較することで、関係の「強さ」を測る別の尺度を構築することもできるだろう。
例えば、前田と友人の中島は、『青い花』のわずか4ページにしか描かれていない(英語版第三巻357-60ページ)。そのため、二人の関係に優勢度はないが、その4ページでは常に一緒に登場しているため、非常に強い関係と解釈することができる。これに対して、ふみとあきらの関係は、数の上ではもっと優勢だが、どちらか一方がいないページも多いので、この尺度ではそれほど強くはない。
だが個人的には、様々な人間関係がどの程度顕著に現れるかに興味があるので、人間関係の強さの代替指標をあえて構築することはやめておくことにする。
ソーシャルネットワークのグラフ化
あるページに登場するキャラクター同士が互いに何らかの関係を持っていることを示す代理指標として、同時出演回数データを改めて使用した、『青い花』作中の登場人物間の関係性グラフを見てみるとしよう。
ここでは、『青い花』の登場人物をグラフのノード(一点)とし、登場ページ数に応じて「ノードの優勢度」を設定する。この値は非常に多岐にわたるので、実際の生のページ数を使う代わりに、ページ数の対数を使う。(ページ数に1を足してから対数をとっているので、1ページしか登場しないキャラクターでも優勢度の値は0にはならない。)
nodes <- char_pct_tb %>%
rename(name = Character) %>%
mutate(node_prom = log(Page_Count + 1)) %>%
select(name, node_prom)なお、この対数変換後の優勢度値でも、最も目立つキャラと最も目立たないキャラの間には桁違いの差がある:ノード優勢度値の最大値は、最小値の9.4倍となる。
このグラフでは、キャラ同時登場数をグラフのエッジ(一辺)とし、あるペアのキャラ同士が一緒に出現するページ数に基づいて「エッジの優勢度」を関連付けることにする。改めて、この値にも大きなばらつきがあるため、生のページ数ではなく、ページ数の対数(正確には、ページ数に1を加えた後の対数)を用いている。
edges <- joint_pct_tb %>%
rename(from = Character.x, to = Character.y) %>%
mutate(edge_prom = log(Page_Count + 1)) %>%
select(from, to, edge_prom)キャラ優勢度と同様、この対数変換後のエッジ優勢度も、最も顕著な関係(ふみとあきらの関係)と最も顕著でない関係との間にはやはり一桁の差がある:最大値は最小値の8.6倍である。
続いて、上記で作成した【nodes】と【edges】の表を使用して、全キャラクター関係の完全なネットワークを構築しよう。
netw <- tbl_graph(nodes = nodes, edges = edges, directed = FALSE)次に、全キャラクターおよび全関係性でグラフ全体を表示したいが、まずは全てのキャラクターが同じような優勢度として扱ってみよう。グラフのレイアウトには、フラクターマンとレインゴールドの力学的アルゴリズムを適用した。
(テーマに【base_family】という値をあえて設定したのは、【theme_graph()】はどうやらWindows特有のフォントをデフォルトとして使っているようだからである。)
set.seed(0)
netw %>% ggraph(layout = 'fr') +
geom_edge_link() +
geom_node_point() +
theme_graph(base_family = "sans") +
labs(
title = "Relationships in Sweet Blue Flowers",
subtitle = "All Characters and Relationships Equally Weighted",
caption = "Data source: \n That Type of Girl, unabridged character index"
) +
theme(plot.caption = element_text(margin = margin(t = 15), hjust = 0))
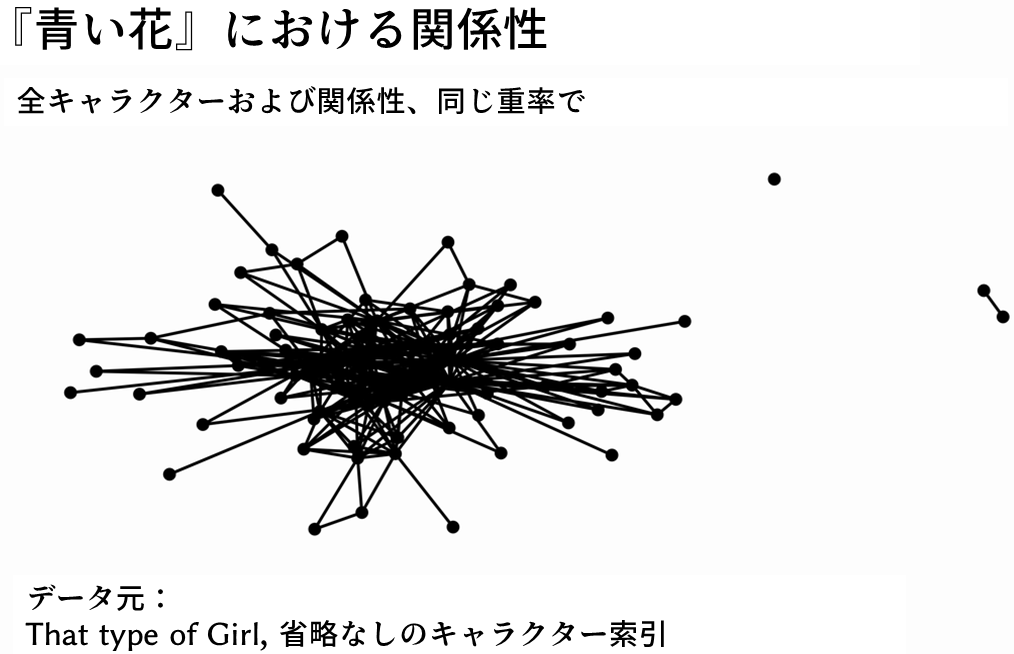
孤立したキャラクターが一人、可南子と、お互いのみとしか交流のないキャラクターが二人、前田と中島である。
最後に、『青い花』で最も優勢度の高い登場人物たちに対応するソーシャルグラフのサブセットを表示しよう。これは、ネットワーク【netw】をフィルタリングして、優勢度順に上位16名のキャラクターを保持したものである。
また、ある関係が「より優勢度が大きい」(【edge_prom】値で測定した関係の上位20%)か「より小さい」(edge_prom値で測定した関係の下位80%)かによって設定される【edge_type】という新しい属性も追加している。
top_characters <- nodes %>%
arrange(desc(node_prom)) %>%
head(16) %>%
select(name) %>%
pull()
top_netw <- netw %>%
activate(nodes) %>%
filter(name %in% top_characters) %>%
activate(edges) %>%
mutate(edge_type = fct_rev(quantcut(edge_prom, q = c(0, 0.8, 1)))) %>%
mutate(edge_size = log(100 - as.integer(edge_type)))そして、この縮小ネットワークをグラフ化する。このネットワークのレイアウトは、関係の優勢度をエッジの太さとして使用することで描かれる。
各キャラクターのラベルの大きさは、そのキャラの優勢度に基づいているが、目立たないキャラのラベルの読みやすさを向上させるために、大きさには下限を設けている。文字と文字の間の線は、優勢度の大きい関係を実線で、小さい関係を破線で表している。また、線の幅も目立つ関係によって変えているが、これも可読性を考慮して範囲を限定してある。
ラベルが左右や上下で切れてしまわないように、【coord_cartesian()】を使ってグラフの境界を明示的に設定している。この境界は試行錯誤で決めたものである;そのためデータを変更するとグラフ自体も変更され、表示されなくなることもあるかもしれない。その場合、境界値を再度調整する必要がある。
また、グラフの再現性を確保するために、乱数発生機にはシード値を設定した;そうしないと、実行するたびにグラフの見え方が多少変わってしまう。選んだシード値に関しては、単にいくつかの値を試してみて、気に入ったグラフができるのを確認してから選んだだけである。
set.seed(1)
top_netw %>%
ggraph(layout = "fr", weights = edge_prom) +
geom_edge_link0(aes(linetype = edge_type, width = edge_prom),
show.legend = FALSE) +
scale_edge_width_continuous(range = c(0.25, 1.5)) +
geom_node_label(aes(label = name, size = node_prom),
show.legend = FALSE) +
scale_size(range = c(3, 6)) +
theme_graph(base_family = "sans") +
coord_cartesian(xlim=c(2.2, 4.4), ylim=c(-1.8, -0.1))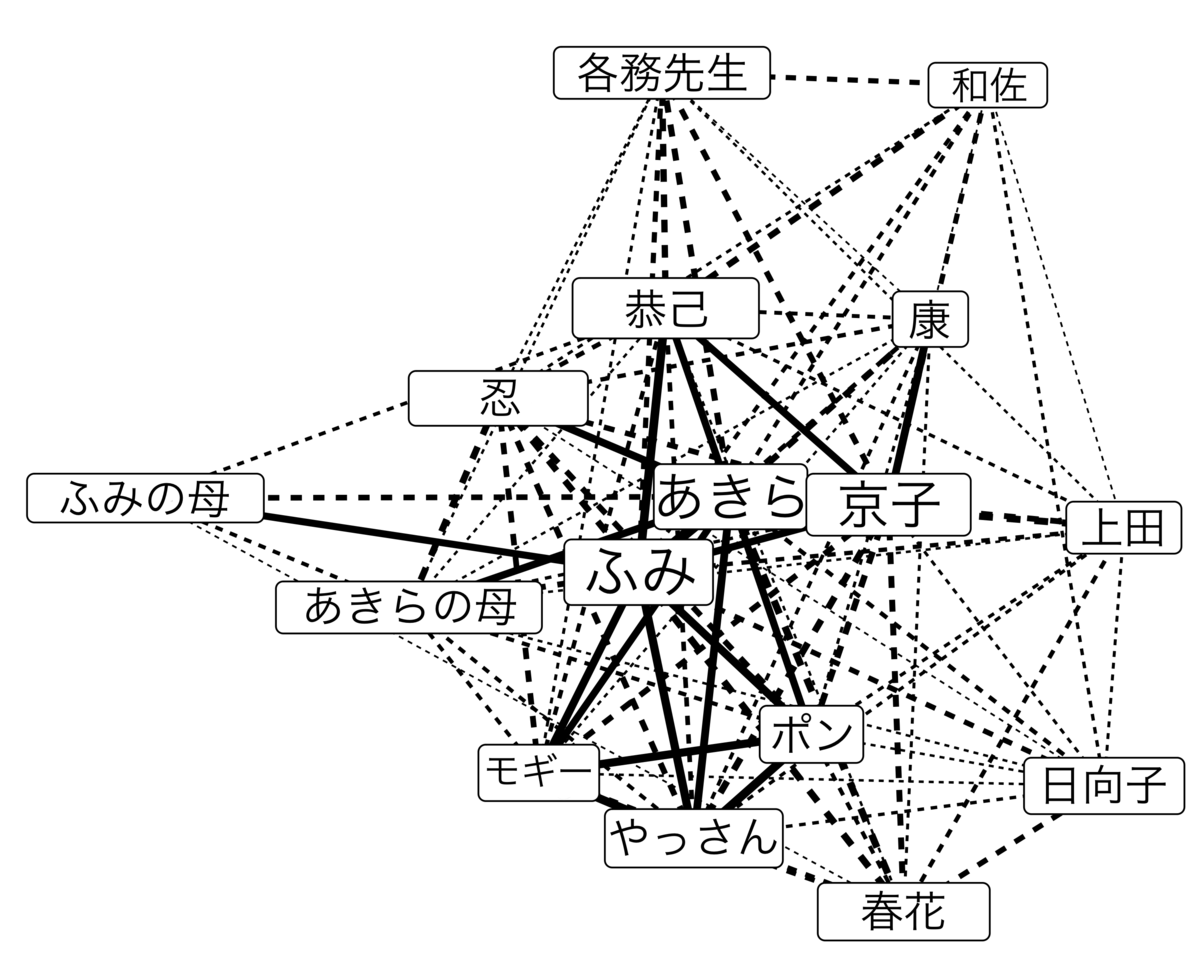
このグラフの見た目は、この作品に対する直感的な理解と一致している;ふみとあきら、そしてこの二人の関係は、予想通り中心的なものである。また、京子と恭己の関係も、これまた予想通り、大きな優勢度となっている。
しかし、それ以外にも、比較的大きな優勢度で取り上げられているクラスターがある。あきらと母および兄;ふみと母;京子と康;モギーとポンとやっさん;恭己と京子とふみとあきらなどである。また、あまり目立たないが、恭己、和佐、各務先生という関係もある。
付録
注意点
同じページ上での二人のキャラクターの登場から関係を推測すると、上記のように偽の結果が出ることがある。これを修正するには、同時登場リストを編集して偽陽性を除去する必要があるだろう。
参照先
この分析に使用した登場人物索引は、もともと私が『そっち系のひと』を書く過程で作成したものである。書籍内の登場人物索引は読みやすくするために多少要約されているが、要約されていないバージョンは『That Type of Girl』の公開リポジトリで利用可能となる予定である。(後述の「ソースコード」の項を参照。)
他の方への提案
同じページで二人のキャラクターが一緒に描かれている回数と、もう一人が描かれておらず単独で登場する回数に基づいた関係の強さの指標を使用して、分析をやり直してみていただければと思う。
また、様々なタイプのソーシャルグラフを作成してみるのも面白そうだ。ggraphレイアウトの紹介を参照してもらえればと思う。
環境について
上記の分析を行うにあたり、以下のR環境を使用した。
sessionInfo()## R version 4.1.2 (2021-11-01)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 20.04.3 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/atlas/libblas.so.3.10.3
## LAPACK: /usr/lib/x86_64-linux-gnu/atlas/liblapack.so.3.10.3
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] tools stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] gtools_3.9.2 flextable_0.6.10 ggraph_2.0.5 tidygraph_1.2.0
## [5] reticulate_1.24 forcats_0.5.1 stringr_1.4.0 dplyr_1.0.8
## [9] purrr_0.3.4 readr_2.1.2 tidyr_1.2.0 tibble_3.1.6
## [13] ggplot2_3.3.5 tidyverse_1.3.1
##
## loaded via a namespace (and not attached):
## [1] fs_1.5.2 bit64_4.0.5 lubridate_1.8.0 httr_1.4.2
## [5] backports_1.4.1 utf8_1.2.2 R6_2.5.1 DBI_1.1.2
## [9] colorspace_2.0-2 withr_2.4.3 tidyselect_1.1.1 gridExtra_2.3
## [13] bit_4.0.4 compiler_4.1.2 cli_3.2.0 rvest_1.0.2
## [17] xml2_1.3.3 officer_0.4.1 labeling_0.4.2 scales_1.1.1
## [21] systemfonts_1.0.4 digest_0.6.29 rmarkdown_2.11 base64enc_0.1-3
## [25] pkgconfig_2.0.3 htmltools_0.5.2 highr_0.9 dbplyr_2.1.1
## [29] fastmap_1.1.0 rlang_1.0.1 readxl_1.3.1 rstudioapi_0.13
## [33] jquerylib_0.1.4 farver_2.1.0 generics_0.1.2 jsonlite_1.7.3
## [37] vroom_1.5.7 zip_2.2.0 magrittr_2.0.2 Matrix_1.3-4
## [41] Rcpp_1.0.8 munsell_0.5.0 fansi_1.0.2 gdtools_0.2.4
## [45] viridis_0.6.2 lifecycle_1.0.1 stringi_1.7.6 yaml_2.2.2
## [49] MASS_7.3-54 grid_4.1.2 parallel_4.1.2 ggrepel_0.9.1
## [53] crayon_1.5.0 lattice_0.20-45 graphlayouts_0.8.0 haven_2.4.3
## [57] hms_1.1.1 knitr_1.37 pillar_1.7.0 igraph_1.2.11
## [61] uuid_1.0-3 reprex_2.0.1 glue_1.6.1 evaluate_0.14
## [65] data.table_1.14.2 modelr_0.1.8 png_0.1-7 vctrs_0.3.8
## [69] tzdb_0.2.0 tweenr_1.0.2 cellranger_1.1.0 gtable_0.3.0
## [73] polyclip_1.10-0 assertthat_0.2.1 xfun_0.29 ggforce_0.3.3
## [77] broom_0.7.12 viridisLite_0.4.0 ellipsis_0.3.2
ソースコード
この分析のソースコードは、本が出版された後、私の『That Type of Girl』の公開リポジトリで参照可能である。
本ドキュメントとそのソースコードは、Creative Commons CC0 1.0 Universal (CC0 1.0) Public Domain Dedicationの条件のもと、無制限に使用、配布、変更することが可能である。より簡単に言えば、どなたでも好きな情報を使って好きなことを自由にすることができる、ということである。

----------
大変丁寧な解説でボリュームがあるため、もう中々雑談するスペースもないのが残念ですが、やっぱり面白いデータですね!
かしまし三人娘の中ではやっさんが一番強い(単独でも、関係性でも)のが意外でしたが、これはやっさんが最終巻で、中学生時代を特に単独でフィーチャーされていたのも大きかったかもしれませんね。
一方、大野の春ちゃんが、単独登場では三人娘の間に割って入る勢いを見せてくれていましたが、他キャラとの関係性となると、やはり学年が違うからか全然顔を見せなかったんですけれど、TOP 20の最後、「あーちゃん/春ちゃん」という僕得なペアがランクインしてくれていて嬉しかったです。
その他の解析、Frankさんが保留にされていた、「強い結びつき(登場全体に占めるそのペアでの登場回数)」なんかも興味深いですね…!
どなたか分析マニアの方が調べてくれることに期待です。
あとは、毎度大変丁寧なコメントをいただけるアンさんから、関係性の記事の時に、
「凄すぎる!ただこれはページ数ということで、コマごとにカウントしたらまた変わってくるのかもしれないですね」
…という旨の感想を受け取っていましたが、まさに僕も同意ですね。
ページ・場面ごとのカウントではなく、コマ単位でカウントしたら、あーちゃん・ふみちゃんの順番とかもまた少し変わってくるのかもしれません。
いずれにせよ、いつまででも・どこまででも分析したくなってしまう、本当に奥が深い『青い花』だというお話でした。
時間があるときに、また気ままにFrankさんの素晴らしいデータを眺めさせていただきたい限りです…!