前回は「ヒトとバナナは60%も同じDNAをシェアしている」という点に触れていましたが、これに関して、またとても鋭い着眼点の疑問コメントをアンさんよりいただいていました。
例えば、今回のソーマチンとお酒分解酵素の比較でいくと、サイズも倍以上違って、何をもってして『半分同じ』と言えるんじゃい?
同じ長さで、1番目と5番目と…って同じになってるものをピックするなら50%と言われてもなんとなく100個中50個が同じだったと思えるけど…
表を見てみたら、単体でも同じと判断されてる感じだし、そもそも4種類しかないわけだから、どれがギャップになるかで結果は変わってこない…??
2個以上連なっているとか、コドン単位とかでもなく、何か法則があるんけ??
これはこの辺のアラインメントの話で誰しもが感じる点でとてもいいご質問だと思いますが、この辺は正直コンピューター科学(計算機科学・アルゴリズム開発)の話で、深追いすると意外とややこしい話になってきます。
まずこれ関連の話で触れておくのが良さそうな点としまして、似たような用語として、similarity(類似性)、homology(相同性)、identity(同一性・一致度)などがあるのですが、研究者版Yahoo知恵袋的なQ&Aサイト・ResearchGateに、ちょうどピッタリの質問が投稿されていました。
https://www.researchgate.net/post/Homology-similarity-and-identity-can-anyone-help-with-these-terms
ベストアンサー(ポピュラーアンサー)に選ばれていたセバスチャンさんの回答が明快で分かりやすい感じだったので、引用させていただきましょう。
A: AAGGCTT
B: AAGGC
C: AAGGCAT
という3つの配列を考えたときに、AとBの一致度(% identity)は100%(5塩基が完全一致)、BとCの一致度も100%だが、AとCの一致度は85%(6/7で一致)となる。
つまり、一致率100%という結果であっても、両者が完全に同一の配列をもつことを意味しているわけではない。
一方、Similarityというのは、そもそも「どれだけ似ているか?」を意味する一般的な用語で厳密な唯一の定義があるものではないが、この類のアラインメント・マッチングの話においては、適宜適当な定義の下で活用される概念である。
ここで、「編集距離」としてSimilarityを定めると(=一方の配列を他方の配列に完全一致させるために必要な、最小の編集操作(挿入、削除、置換)の数)、AとBの類似度は60%、AとCの類似度も60%、そしてBとCの類似度は86%となる(セミグローバルな計算式に基づく:類似度=1-(編集距離/短い方の配列の、位置合わせされない部分の長さ))。
ただし改めて、Similarityというのは異なる定義のものが用いられることもある。例えばタンパク質の三次元構造を用いたものなど。
…という感じで、セバスチャンさんのいう「類似度」であれば、AとBよりAとCの方が類似度は高くなるため、これは直感的にもより現実を言い表しているように思えますね。
(ちなみに、計算式はどういうことなのか一瞬悩みましたが、AとBは編集距離2(2塩基の挿入)で不動塩基が5なので、1-(2/5)=60%、AとCは編集距離1(1塩基の置換)で不動塩基7なので、1-(1/7)=86%って感じですね。)
要は、前回のソーマチンとお酒分解酵素の計算では、一致度(Identity)だけを見ていたので、これは正直全く現実を表していなかったといえる形です。
ここで定義される「類似度」であれば、ソーマチンとお酒分解酵素は、極めて低い類似度になることでしょう。
結局、配列のアラインメントでは一致率よりもむしろ類似度に着目すべきといえますが、類似度は用いるソフトウェアが採用するアルゴリズムなどによって定義が異なるので、単純に「こういうもの」とはいえない数字であるというのが悩ましい点といえるかもしれません。
例えば前回のバナナは、原典のBusiness Insider記事内、本文中では「Even bananas surprisingly still share about 60% of the same DNA as humans!」と、「60%のDNAをシェアしている」という、何を意味するのかが漠然とした、かなり逃げた表現が使われていました。
一応前回も貼った画像の中では、「The genetic similarity between a human and a banana is: 60%」と、similarityという用語は使われていたものの、上述の通りsimilarityというのも定義が漠然とした用語なので、これがどういう意味での類似性のことを指していたのかは、元データにあたってみないと分からない感じですね。
こちらは学術論文ではなく読み物ニュース記事なので、引用論文も掲載されておらずオリジナルのソースは辿れませんでしたが、まぁ、流石にソーマチンとお酒分解酵素で見たような、「単純アラインメントでの一致塩基で60%」だと、正直それはほぼランダムなものに過ぎないので、もうちょいちゃんと現実を反映した計算法での60%なのかな?…とは思いますが、しかし言ってもヒトとバナナですからね、やっぱり大分ズルいというか、正直あまり実際を表しているわけではない、かなりミスリーディングな数字が使われている可能性も否めない気がします。
とりあえず1点補足の補足に戻っておくと、先ほど挙げていたもう1つ似たような用語であるhomologyについて、これはResearchGateのページ内で結構議論がされている通り、こちらは進化学の用語であり、「同一祖先をもつ分子といえるかどうか?」を示す言葉になるので、「『homology(相同性)が○%』という言い方はしないで!homologyは、バイナリ(0か1か。homologyがあるかないか)の概念だから!!」ということが強調されていた通り、使用には注意が必要な用語かもしれません。
つまり、「ヒトtRNA-HisとマウスtRNA-Hisは相同性がある」「ソーマチンとALDH2には相同性がない」と、そういう感じで使う用語ってことですね。
(ResearchGateでも間違ったことを書いている人が散見された通り、割とその辺ガバガバで使われることが多いですし、僕自身も正しくない使い方で『相同性』って言葉を使っていた場面が以前の記事にあったかもしれません。まぁその辺は雰囲気でよろしく、という感じで…。)
一応生命科学系を専攻する人にとっては結構重要なポイントになりますが、まぁ細かすぎますし、入門的には気にしなくてもいい範疇の話でしょう。
そしていただいていたご質問で聞かれているポイントに戻ってみると、そもそも前回のCLUSTAL Omegaのアラインメントでの、一致塩基の判定はどうなっとるん?…という点も疑問点の中心の1つだったように見受けられますが……
こちらは、正直完全にバイオインフォマティクス(生命情報科学)系の話で、どういうアルゴリズムが組まれているか僕は専門外でモグリなので正直詳しくは分からないですけど、まぁ普通に考えて、最も一致度が高くなるように(=一致する塩基が多く、かつ、ギャップが少なく。どちらをどのように優先しているかとかは、それこそツールの設計者の定義次第としかいえない感じです。そういうより良いアルゴリズムを研究しているのがバイオインフォマティクスで、生物というより数学に近い研究分野ですね)、コンピューターが計算して求めた結果が表示されている、って形であろうと思われます。
しかし改めて、一致率は(特に4文字しか存在しないDNA配列の場合)さほど意味のある数字にならないことが多いので、
(もちろん、「自分が実験でプラスミドに導入した遺伝子のシークエンスを読んで、データベースと一致しているかどうかチェックしたい」ような目的の場合、一致率を見るのは十分意味がありますけどね。DNAのCLUSTALWとかですと、そういう用途で使うことも多いです)
…前回は話のネタの例として一致率の数字を見ていましたが、異なる生物や異なる遺伝子の配列アラインメントでどれだけ似ているかを調べる上では、それよりもっと適するデータがあるといえる感じだったのです。
実は、何度か見ていたBLASTサーチには、それに打ってつけのデータが用意されているのでした。
せっかくなので(本当に細かすぎて、ぶっちゃけあんまり面白くもないですけど)、ちょっとそちらも見ておくとしましょう。
新しい例として、今回はソーマチン遺伝子DNAの配列を、対象を全生物のデータに広げて、BLASTサーチを行ってみました。
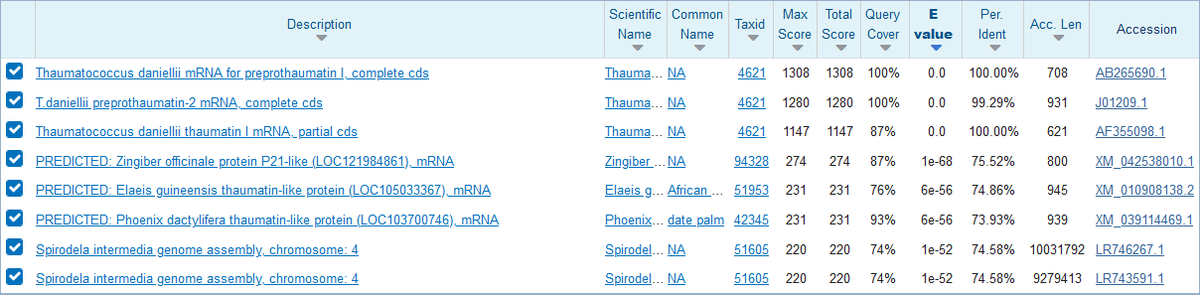
例によってコンピューターが「似てる」と判定した配列が列挙されていますが、そもそもこれは上から順に「類似度が大きい」ものが並んでいるわけですけど、実は、一致度(Per. Ident)順に並んでいるわけではないんですね。
そう、BLASTサーチ結果の順番は、デフォルトでは、E value順に並んでいるのです!
E valueとは?
こちらは、Expectation value、いわば期待値のことですが、よくいわれる期待値ではなく、「両者が(本当は全然関係ない配列なのに)偶然一致してしまった確率」のことを意味しています。
つまり、この数字が大きければ大きいほど、「一致したのは偶然だぞ」という可能性が高く、類似性は疑わしいものとなるわけで、こちらは小さければ小さいほど信用できる類似性がある、ってことになるんですね。
科学、特に生命科学の世界では、数学のように厳密なことは決して言い切ることができないので(何せあらゆる生物には個体差がありますから)、こういう表現が多用されます。
断言はせず、ただ単に「偶然これらが似た配列になってる確率は○%」というだけで、それが小さいかどうかはあなた自身が判断してください、って形になってるわけですね。
(まぁソーマチン最初の3つは0.0で、「偶然ヒットした確率、0%!」と断言しているように見えますが、これはあまりにも小さすぎて表記できないから0.0となってるだけで、0と断言はしていないはずです。
なお、その下の1e-68というのは、10のマイナス68乗のことで、「0.」の後に0が67個並ぶ数字、これはちょうど都合よく日本語で表記できる最小(最大)の数である、「10の無量大数乗分の1」という感じですね。
「無量大数」は、小学生の子供とかが無限と同じ意味で使いがちですが、これはれっきとした数を表す言葉で、10の68乗が無量大数ですね。10の3乗を千、10の12乗を兆と呼ぶのと同じ感じです。
…多分、最初の3つは、e-100以下の確率、って感じではないかと思われます。)
いうまでもなく、10の68乗分の1という超低確率の事象が偶然起きることはあり得ないので、これは絶対に意味のある類似性だ、と結論付けができるわけですが、あくまで科学的には「両者は同じものとは限りません。偶然一致しちゃった確率が、無量大数乗分の1ぐらいはあるかも」と、断言はしていないってことですね。
まぁこのE valueはある意味信頼度の話なので、より分かりやすく類似度を示す数字は何かというと、その横にある「スコア」なんかがそれともいえますね。
詳しいスコア判定方法は、これもまぁ設定次第で変えられるものであり、僕は詳しくは存じ上げませんが、JAICI(化学情報協会)がまとめてくれていたBLASTマニュアル(https://www.jaici.or.jp/stn/pdf/seqfaq.pdf)によると、デフォルト設定では、塩基が一致すると+1点、不一致だと-3点するような感じで、さらにギャップが入ると適宜減点…みたいな形のようですが、もう細かい点はともかく、「一致すればするほど高い点になるように、偉い人が決めてくれた判定」と素直に受け止めればOKでしょう。
ちなみに、Max Scoreというのが1つの遺伝子での最大スコア、その横のTotal Scoreは異なる遺伝子も含めて、同じ項目でまとめてヒットしてきた全部を合計したスコア(例えば同じ染色体に複数の遺伝子のヒットがある場合とか、以前一部のtRNAの例で見ていました)ですね(…って、ややこしすぎますし、ぶっちゃけどうでもいいでしょう)。
まぁ「スコアいくつから似てるといえるのか?」については正直なんとも断言できかねますが、こないだ見ていたヒトと酵母のtRNA-HisのBLAST結果を改めて見てみると、最大スコアは52.7だったので、これは生物種は違えど同じtRNA-Hisだし割と似てなくはなかったので、まぁ少なくとも50あればかなり関連性はあるのかな、とはいえそうですかね?
(またちなみに、酵母tRNA-Hisでヒットした配列のE valueは3e-07でした。これはつまり、偶然一致した確率が0.0000003、すなわち1000万分の3の確率で、「この遺伝子は、たまたま無関係なのにヒットしてきた」ということですから、普通の常識で考えて、これは偶然などではない、意味のある類似といえましょう。)
最後改めてソーマチンのBLAST結果に戻ってみますと、ソーマチンそのもの(Thaumatococcus daniellii(ソーマチンを作る植物の学名でしたね)ゲノム由来)の遺伝子以外に、若干落ちるスコアとして、別の植物の「ソーマチン様(よう)タンパク質」というのもいくつかヒットしていました。
一番低いウキクサの一種Spirodela intermediaのゲノムにある遺伝子でも、解析に投げた配列の74%程をカバーしており(外れた26%は、類似度が低すぎるので無視)、その中でさらに74.58%が一致塩基だったということで、まぁ多分その程度の類似度だとチョイ甘タンパク質なのかな?って気はしますが、どうなんでしょうねぇ~。
確かに、ウキクサって何か甘そうな気も、しないでもないかもしれません(いや食べたことないし、そもそも言っててウキクサのイメージなんて全然できてませんが(笑)。一応、調べたら、こんなの(↓)ですね)。
…と、類似度判定について、何だかごちゃごちゃ分かりにくい話になった気もしますが、結局、似てるかどうかは最終的には主観に依存する、でも、その主観に多くの人が納得できるかどうかは、客観的な数字で表現されている…という、なんとも小難しい話になるってのが結論かもしれませんね。